Jonathan's Final Report
Introduction
So it's the end of the semester, and it is time to go through some of the things we have learned so far. The reason I choose this course is because while doing research in the field of computer vision, I felt the need to learn more background knowledge, and also because I was told that this course would focus more on neural networks towards the end.
We humans are very good at recognizing patterns, so good that we often don't even need to think about it. Recognizing a face, or a voice is just a piece of cake. However for a computer, these tasks are quite difficult.
If we really look in to the problem, we will see that the abilities that we take for granted are actually pretty complicated. For example, recognizing the face of a human. First, we need to find the face, and then we need to find out what is special about this face, finally we store this information for future use of comparison. Up until here it still seems very straightforward, but there is one more thing that hasn't been considered, the real world environment. The real world has shadows, occlusions, special cases and much more, which makes pattern recognition even more challenging. It’s amazing how we humans can focus only on what is important, and ignore the rest. And is one of the reasons why I am extremely interested in the topic neural networks.
Neural networks has been a hot topic in the research industry for the past few years, and has been gaining popularity ever since. The reason for that is because there have been some important breakthroughs in research and technology. As research goes, we find some new thing every day, and since the research in neural networks has started since the 1950's, researchers have found some interesting properties in how to train neural network and how to implement them more easily. Technology on the other hand, computers are becoming faster and cheaper, and with the help of GPUs, parallel computing in neural networks speeds up the training process, what took days, now may take only hours to achieve, which is a great step forward.
Non-linear classifiers
As said before, the world is not perfect, therefore, when doing classification, linear classifiers just won't cut it. It's often hard or even impossible to find linear correlation when classifying objects in the real world environment. That is why people started to do research on non-linear classifiers, there are various methods to do non-linear classifiers, the one that i am most interested in is neural networks.
Neural networks were an attempt to mimic biological neuron networks, and try to make a computer learn as how a human would learn. But in the early stages, when computers were not as advance as today, the lack of computational resource made researchers in that domain skeptical about the
So it's the end of the semester, and it is time to go through some of the things we have learned so far. The reason I choose this course is because while doing research in the field of computer vision, I felt the need to learn more background knowledge, and also because I was told that this course would focus more on neural networks towards the end.
We humans are very good at recognizing patterns, so good that we often don't even need to think about it. Recognizing a face, or a voice is just a piece of cake. However for a computer, these tasks are quite difficult.
If we really look in to the problem, we will see that the abilities that we take for granted are actually pretty complicated. For example, recognizing the face of a human. First, we need to find the face, and then we need to find out what is special about this face, finally we store this information for future use of comparison. Up until here it still seems very straightforward, but there is one more thing that hasn't been considered, the real world environment. The real world has shadows, occlusions, special cases and much more, which makes pattern recognition even more challenging. It’s amazing how we humans can focus only on what is important, and ignore the rest. And is one of the reasons why I am extremely interested in the topic neural networks.
Neural networks has been a hot topic in the research industry for the past few years, and has been gaining popularity ever since. The reason for that is because there have been some important breakthroughs in research and technology. As research goes, we find some new thing every day, and since the research in neural networks has started since the 1950's, researchers have found some interesting properties in how to train neural network and how to implement them more easily. Technology on the other hand, computers are becoming faster and cheaper, and with the help of GPUs, parallel computing in neural networks speeds up the training process, what took days, now may take only hours to achieve, which is a great step forward.
Non-linear classifiers
As said before, the world is not perfect, therefore, when doing classification, linear classifiers just won't cut it. It's often hard or even impossible to find linear correlation when classifying objects in the real world environment. That is why people started to do research on non-linear classifiers, there are various methods to do non-linear classifiers, the one that i am most interested in is neural networks.
Neural networks were an attempt to mimic biological neuron networks, and try to make a computer learn as how a human would learn. But in the early stages, when computers were not as advance as today, the lack of computational resource made researchers in that domain skeptical about the
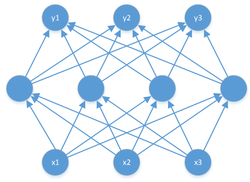
Figure 1 Fully connected network
There is actually no exact method of how you should design a fully connected network. Because there’s no way that you would know in advance how your network would perform based on how many layers you have, or how many neurons you have each layer. The only thing that is certain is that small networks are good at learning simple problems, and large networks are good at solving complicated problems,
Learning of a network
How to train a network was an important research topic in the realm of neural networks, the goal is to find the right weights in order for the network to do the assigned task. Gradient Descent was one of the earliest learning methods developed.
The development of gradient based learning algorithms was an important step forward. Most of today's learning algorithms are based on Gradient Descent, such as Stochastic Gradient Descent. The main differences between the two is that Gradient Descent tends to use all the training samples to find the right gradient. While Stochastic Gradient Descent randomly chooses a training data and updates the weights using the gradient calculated using that chosen data. Thus Stochastic Gradient Descent is faster, because the less calculation needed when calculating the gradient, but less accurate. Stochastic Gradient Descent with mini-batch wants to combine the advantages of traditional Gradient Descent and Stochastic Gradient Descent. It separates the training data into small batches and trains the network using those batches. Each epoch, a random batch is chosen, and Gradient Descent is used to update the weights.
However, when it comes to multi-layer networks, or in other words, networks with hidden layers, the information given at the output layer would not be efficient to use Gradient Descent, There is no information on what the hidden layer's weights should look like. Therefore, the back propagation algorithm was developed. Back propagation first does a feed-forward pass to get the output of the current network, then it compares the output with the desired output to get the error. The error then propagates backwards through the network to calculate the error of each layer, finally it uses gradient descent to update the weights of each layer. It seems very simple, but very useful when learning multi-layer networks.
Finally, after we know the training of a network, another problem arises. Over-fitting. We said that neural networks can learn any function, and nothing in the real world is perfect, Thus causes a problem, the network learns too much information, and by too much, I mean it not only learns the assigned task, but also learns the noise that came in with the data. This is called over-fitting, to solve this problem, generalization is needed. A technique called dropout is used,
Dropout is a technique used in training, the goal is to avoid over-fitting. Over-fitting is often caused by noise or special cases getting learned as actual data and thus makes the network less generalized. In each epoch of training, random neurons are dropped out of training to avoid each neuron learning all data. Thus makes the network less susceptible to noise.
Convolutional Neural Networks
Convolutional Neural Network is inspired by the biological visual system, It uses a concept called the local receptive field. If you were to visualize it, it would look something like figure 2.
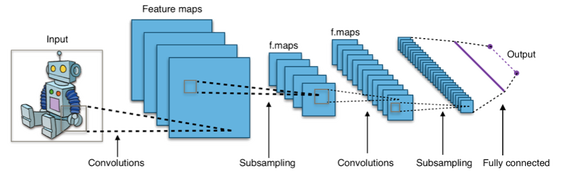
Figure 2 Convolutional neural network
The advantage of this kind of network is that the network takes consider of local features, and generates features using learned weights. Also because it is convolutional, the network uses a set of weights and shares it across the whole image. Therefore, less weights needs to be used. Thus smaller models and faster computation times.
In this course, I have done two program examples, the first is MNIST handwritten digit recognition, and the second is INRIA Prdestrian detection. The program language I choose to use is Python, and for easier implementation, I used a framework call Tensorflow. Tensorflow is a neural network framework developed by Google.
In the first example, I used two convolutional layers, and two fully connected layers and a softmax output. Each convolutional layer has a 5 * 5 mask, and the first layer produces 32 feature maps and the second layer produces 64. Next, the first fully connected layer has 1024 nodes, and the output layer has 10, the network uses dropout to avoid over-fitting. I used cross entropy as the cost of the network, and Adam Optimizer, a stochastic training algorithm to train the network. MNIST is the database I used to train the network, it contains 60000 training examples and 10000 testing examples, figure 3 shows a partial example of the database. Partial of the code is shown in figure 4.

Figure 3 MNIST Dataset

Figure 4 Handwritten Digit Recognition Partial Code
We can see that by using Tensorflow, how easy it is to define a complex network, and training is easy too. After choosing a cost function and an optimization function, the rest is all done by Tensorflow. A training output is shown in figure 5.

Figure 5 Handwritten Digit Recognition Training Output
By training 10000 steps, the accuracy has reached 99% and figure 6 gives a recognition example.
Figure 6 Handwritten Digit Recognition Evaluation Output
It is interesting how such a network can learn such a task so easily and with high accuracy. Another program i wrote was a program i wrote out of curiosity. I used a similar network architecture, but I tried to train it to detect pedestrians. Here I used three convolutional layers, and three fully connected layers and a softmax output. Each convolutional layer has a 5 * 5 mask, and the first layer produces 18 feature maps and the second layer produces 36 and the third produces 72. Next, the first fully connected layer has 8192 nodes, and the second layer has 2048, and the output layer has 2 nodes, the network uses dropout to avoid over-fitting. I used cross entropy as the cost of the network, and Adam Optimizer, a stochastic training algorithm to train the network. The database I used is the INRIA pedestrian database, Training images contains 2416 positive images and few no pedestrian images to extract negative images, Testing images contains 1132 positive images and also a few images to extract negative images. Figure 7 shows some samples of the INRIA database. And figure 8 shows the partial training results.
Figure 7 INRIA Database
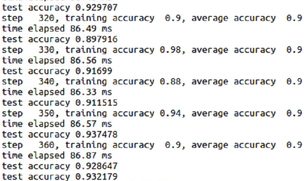
Figure 8 Pedestrian Detection Training Output
We can see that high results have been achieved at early stages of training, and testing results show promising outputs, such as figure 9, but despite its high accuracy on the test data, if we try to use it in a more real world environment, such as figure 10, we can see that the network doesn't actually work as great. The blue rectangle are the places that the network thinks where pedestrians exist.
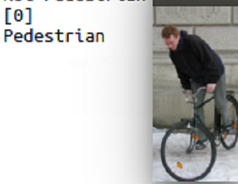
Figure 9 Pedestrian Detection Evaluation

Figure 10 Pedestrian Detection Real World Failure
Conclusion
In pattern recognition, neural networks are an interesting topic to do research on. After taking this course, I have learned a lot on the fundamentals of pattern recognition and neural networks, it is very interesting how such simple neuron when constructed into a network can learn to do such complicated task. It is a mystery on what the trained weights mean, but it is proven that although a blackbox system, it does the task. I also like the fact that I tried to implement some networks by myself, although the pedestrian detection wasn't ideal, but more research is needed. If I can make a perfect detector by just taking one course, then the research progress of neural networks should be more advanced by now.
In pattern recognition, neural networks are an interesting topic to do research on. After taking this course, I have learned a lot on the fundamentals of pattern recognition and neural networks, it is very interesting how such simple neuron when constructed into a network can learn to do such complicated task. It is a mystery on what the trained weights mean, but it is proven that although a blackbox system, it does the task. I also like the fact that I tried to implement some networks by myself, although the pedestrian detection wasn't ideal, but more research is needed. If I can make a perfect detector by just taking one course, then the research progress of neural networks should be more advanced by now.
